RxJava原理
我在前面提到了几个问题,下面将尽可能的试着把它们说明白。
- map函数的Func是以什么形式,存储在哪里,在何时,由谁操控着,来处理订阅和观察的结果(参数)的?如果有n层map,那么这种关系将较为复杂。
- flatMap是怎样的原理?和map有什么区别
- 线程是如何生效的?
- subscription在unsubscribe的时候,仅仅取消了订阅者的关注,还是停下了整个调用链?
从map函数说起
如果我们自己构造map函数的时候,我们会怎么构造?
我是这样想的,我会定义一个Subscriber来接收,同时穿件一个新的Observable来发送新的信号,当接收到一个信号的时候,处理,然后就由新的Observable发送一个。
在这中间,或是在Subscriber,或是在Observable中用Func来处理Event。即可达到map的功能。
1 | Subscriber mFatherSubscriber = null; |
这样确实可以实现map的功能,但是对比RxJava的实现,有以下几点不足,或者说没有考虑到。
第一,打破了完全的函数式编程结构。这样的话需要给Observable留出转发的接口,而Observable对应着的却是产生事件的行为,没有接收信息的行为。而给他加上这个接口,整个思想就会造成混乱,无法让用户很好的体验到事件流的魅力。
第二,各个级别拆的太散了,想要控制后面的行为,比如控制后面的map执行的线程,就需要把这样那样的信息也传递下去。这需要预留大量的接收入口,不太好。
第三,更加复杂的结构,比如flatMap相对来说,就不好兼容。而RxJava却用Operator类将所有的行为统一到了一起。
那么RxJava是怎么实现map的呢?
用自然语言描述。
我先用语言简单描述一下,然后再深入到代码中。
在研究map之前,我想再啰嗦一遍subscribe()函数运行的过程。
在subscribe函数中,有两个操作对象,一个是被调用的Observable事件源,一个是传进来的Subscriber接收者。
当subscribe调用的时候,就会把Subscriber交给Observable,由Observable来进行调用。
代码如下:
1 | public void static subscribe(Subscriber s, Observable o) { |
总之,会有一个动作,就是把Subscriber交给Observable里的OnSubscriber,并进行进一步处理。
OK,让我们回到map的问题上。
当执行map(Func)的时候,会构建一个新的Observable(这个构建的过程叫做lift())。如果紧跟着map后面调用subscribe的话,那么一个Subscriber就会被交给这个Observable。
那么这个新的夹在数据源Observable和订阅者Subscriber之间的Observable都做了哪些事呢?
这个Observable会把接收到的Subscriber首先包装成一个新的Subscriber,新的Subscriber会把传来的信号先经过Func处理,然后再交给被包装的那个Subscriber。
然后介于中间的Observable会把这个包装过的Subscriber交给上一级的OnSubscriber来处理。上一级的OnSubscriber中也可能有自己的处理方式,比如再把Subscriber包装一层,直到遇到真正的数据源,开始给这包装了一层又一层的Subscriber传递数据,这一层又一层的包装,就是一层又一层的中间函数处理。
用代码描述
我们依旧从map函数看进去,然后了解Operator类,以及lift函数。
Observable#map方法
1 | //T是当前所在的Observable实例的T泛型,代表这一级传递过来的参数的类型, |
OperatorMap
1 | public final class OperatorMap<T, R> implements Operator<R, T> { |
所以,我们归纳一下OperatorMap的作用。暂时存储Func1,需要的时候,就会把传进来的Subscriber包装上Func形成新的Subscriber。我们可以说,这个Operator生成了一个新函数,返回了出来。有点函数式编程的意思了吧。
Observable#lift函数
1 | //注意参数这个final,这个Operator将被保存在内部类中,其中的函数也得到了保存, |
所以我们就可以解答第一个问题了。
map函数的Func是以什么形式,存储在哪里,在何时,由谁操控着,来处理订阅和观察的结果(参数)的?如果有n层map,那么这种关系将较为复杂。
map函数的func储存在Operator中,Operator储存在map函数返回的新的Observable中,以闭包的形式保存在实例中。
在调用subscribe的时候才会被使用,首先由Operator包装到下级传上来的Subscriber上面。然后再统一传给上级,最后,传到源头的时候,就会被调用。
先溯流而上,不断包装,不断保存下设置的信息,不管是函数也好,线程控制也好通通都会被包装被记录下来。溯流到源头以后,数据源传递过来的数据,就会沿着各层包装制定好的路线一次运行。
控制数据的流向——flatMap
前面已经说了,RxJava优势的第二点是明晰的事件流模型,这个所谓的流反应在时间上,一段时间内持续不断的有事件传来,形成一个流,如何控制这种流,流量,流向,ReactiveX都提供了相当优雅的解决方案。
flatMap的作用
我首先还是用自然语言来简单介绍一下flatMap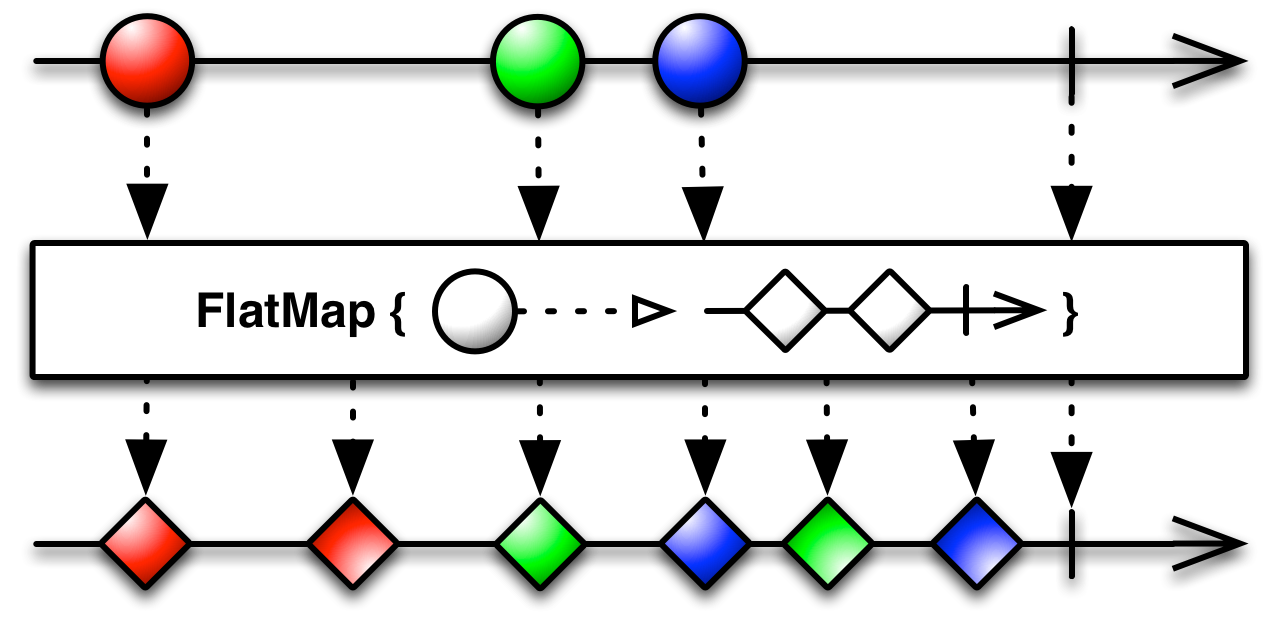
flatMap接收一个事件的数据,返回一个Observable。这是什么意思呢,函数内部会首先执行这个新返回的Observable,把这个Observable的事件全部都发给Subscriber,再接着返回源头的Observable,继续给flatMap发事件,以此类推。
flatMap原理
1 | public final <R> Observable<R> flatMap(Func1<? super T, ? extends Observable<? extends R>> func) { |
首先Fuc经过了一层map,这意味着map返回的是一个Observable
然后再看merge函数,merge函数将对这个Observable再向下处理一层。(现在Rxjava所谓的Observable串的结构体系已经初现端倪了)
merge()发生了什么呢?
1 | public final static <T> Observable<T> merge(Observable<? extends Observable<? extends T>> source) { |
source对应着map返回的一个Observable,这个map返回的Observable传递的是Observable信号。对它进行lift,意味着用OperatorMerge接收下级Subscriber进行包装生成新的Subscriber。再交给上级的Observable。这个新的Subscriber接收的是Observable
所以答案就呼之欲出了,就是把Observable
我们来归纳下,merge函数的作用,能够把Observable
线程是如何生效的
1 | public final Observable<T> observeOn(Scheduler scheduler) { |
在事件源执行时,通过OperatorObserveOn对于Subscriber进行包装。
其实这层包装,就是一层线程切换,决定了,接下来的任务(下级的Subscriber,或者说内层的Subscriber)在哪个线程执行。
1 | public final Observable<T> subscribeOn(Scheduler scheduler) { |
nest其实就是把现在的Observable进行返回。我们姑且把这个叫做obs_A,对它进行lift意味着,把传给它的Subscriber先用OperatorSubscribeOn进行包装,然后再交给上级Observable进行执行。
也就是说obj_A返回的Observable,会交给OperatorSubscribeOn生成的新Subscriber,而新Subscriber保存着内层的Subscribe。再进行进一步传递。于是,就有了机会在这中间进行线程的切换。
Subscription#unsubscribe方法
OK,现在我们已经很清楚,每一个map,flatMap,subscribeOn,observeOn等等等,其实都是构建了一个新的Observable,也就是说构成了一个Observable串。
那么,当调用unsubscribe的时候,发生了什么呢?是整个Observable链条每一节都会断掉吗?
unsubscribe方法是Subscriber里的一个方法
1 | public abstract class Subscriber<T> implements Observer<T>, Subscription { |
看起来,所有的Subscriber都被存储在一起了,我们再看一下SubscriptionList。
1 | public final class SubscriptionList implements Subscription { |
从上面代码中看,其实就是调用一个Subscriber的unsubscribe的时候,就是对于在SubscriptionList中的所有Subscriber调用unsubscribe。
那么SubscriptionList中都有哪些Subscriber呢?
我们知道Operator的实质是对Subscriber进行包装。
1 | @Override |
我们看到,包装过的外层的Subscriber,在构造的时候,会把内层的订阅者传进来。
我们来看一下Subscriber的构造函数。
1 | protected Subscriber(Subscriber<?> subscriber) { |
于是所有的Subscriber其实都共享着同一个SubscriptionList,换句话说,记录了所有的Subscriber。同时SubscriptionList还有一个boolean型的标记,标记着是否已经停止。在需要时,就会针对这个进行类型进行判断,看是否该终止这一发送行为。
以下是Observable.from(Iterable)对应的OnSubscriber的call函数。
1 | @Override |
我们可以看到在这个函数中,就对于是否已经停止订阅进行了判断。
所以,当我们调用unsubscribe的时候,整个Observable调用链,不一定全部断裂,而是看需求,有需求(持续发送信号)的Observable,就会判断Subscriber是否停止接受。而Subscriber之所以可以看到最底端,或者最内层的Subscriber是否接收信号,是因为他们共享着同一个SubscriptionList作为判断标识。
所以,要注意,unsubscribe只是标明Subscriber对于这个事件源不感兴趣了,但是不意味着,Observable以及中间层的各个Observable会立刻停止发送信息,有时,即便没有了订阅者,Observable也还是会继续发送信息。